Open-Sourced vs Closed-Sourced Large Language Models

This series of tutorials are dedicated to exploring Large Language Models (LLMs) and their real-life applications across various use cases. If you’ve missed any previous posts, you can catch up on them here (links attached):
- Gentle Introduction to Large Language Models
- Semantic Search and RAG with Large Language Models
- Open-Sourced and Closed-Sourced Large Language Models
- Comprehensive Guide on Prompt Enginerring
- Enhancing LLM Performance with Vector Search and Vector Databases
Do not forget to subscribe in order to receive the practical use-cases in the world of NLP.
For those who eager to delve deeper into the world of LLMs and Natural Language Processing (NLP), please feel free to join to the LLMs Zoomcamp course by DataTalks Club. It’s completely free.
This Zoomcamp offers a wealth of information on LLMs, their practical applications, and, most importantly, connects you with a community of open-minded professionals. Whether you need professional advice or career guidance, you’ll find support from experienced Data Engineers, Machine Learning Engineers, and Data Scientists. Join community to share knowledge and grow together.

Open-Sourced vs Closed-Sourced LLMs
Before diving into the main topic of optimizing LLMs (the part of Prompt Engineering), let’s briefly discuss the difference between open-source and closed-source LLMs. You’re probably familiar with closed-source models. These are proprietary models developed by companies like OpenAI, Anthropic, Mistral, Meta, Microsoft, and Google. Such models are not freely available to the public; they are typically accessed through APIs provided by these companies, and usage often comes with a fee. Additionally, the underlying architecture and technical details of these models are usually not disclosed and model’s weights are not distributed.
Closed-source models often boast larger sizes and higher quality, making them excellent candidates for certain applications. However, their closed nature means you have less control and flexibility over how they are used. And there are always limitations on situations where you can or can not use them.
On the other hand, there are numerous open-source LLMs that are freely available for anyone to use. These models, along with their code and weights, can be obtained without any cost. While open-source models might require some optimization to suit specific use cases, they offer the advantage of full transparency and control. In many practical scenarios, open-source models can perform just as well, if not better, than their closed-source counterparts.
What to choose?
The decision to use open-source vs closed-source models depends on several factors, including your infrastructure, the data available for fine-tuning, your budget, and specific use case requirements. If you have a flexible budget, prefer simplicity and want to pay money to the third-parties, closed-source models can be a convenient option.
Open-source models are ideal if you need more control over the model’s behavior and want the flexibility to customize it for your specific needs. These models can be fine-tuned to better fit your application and are free to use, making them an attractive option for those on a tight budget.
While closed-source models are often more advanced, open-source models have made significant strides and can offer competitive performance. With proper optimization and fine-tuning, open-source models can meet or even exceed the performance of paid APIs in some use cases.
Where to find Open-Sourced LLMs?
One of the most well-known platform for pre-trained models is Hugging Face, which is highly adopted among machine learning practitioners. Hugging Face’s library, Transformers, includes a vast collection of models like Llama3, Phi-3, GPT-2, GPT-3, and RoBERTa, catering to a wide range of tasks such as text generation, classification, and named entity recognition.
Hugging Face is known for its user-friendly interface and extensive resources, making it easy for both beginners and experienced developers to find and implement models. The platform offers numerous tutorials and learning paths, helping users to get the most out of their chosen models.
Before using a specific LLM from Hugging Face, it’s essential to review the model’s card. The model card provides detailed information about the model, including:
- Tokenization: Specific tokens required for the model.
- Prompting: Guidelines on how to structure prompts to get the best results.
- Nuances: Any peculiarities or special instructions for using the model effectively
- How-to use: Usually a chunk of code showing how to run inference for the specific model
Understanding these details ensures that you can leverage the model to its fullest potential and achieve relevant, high-quality results.
In order to start with Hugging Face’s models you need to install a couple of libriaries that are created and distributed by Hugging Face:
$ pip install -U transformers accelerate bitsandbytes sentencepiece tiktokenOne important remark: in order to run the most LLMs that are distributed across Hugging Face you need to have a capable GPU otherwise such options as Cloud Platforms or Google Collab are available for you.
Let’s see how we can integrate the open-sourced models into our RAG functionality that we have created in the previous post “Semantic Search and RAG with Large Language Models (LLMs)”.
Note: The LLMs that will be downloaded from Hugging Face Hub usually are large enought and you need to be sure that you have enought space on you disk. By defaul the models are downloaded:
Windows
- C:\Users\username\.cache\huggingface
macOS X and Linux:
- ~/.cache/huggingface/hub
If you want to change the location where the model will be downloaded you should set a new environment variable called HF_HOME
import os
os.environ['HF_HOME'] = 'your path'Collect and preprocess data:
import requests
import minsearch
docs_url = 'https://github.com/DataTalksClub/llm-zoomcamp/blob/main/01-intro/documents.json?raw=1'
docs_response = requests.get(docs_url)
documents_raw = docs_response.json()
documents = []
for course in documents_raw:
course_name = course['course']
for doc in course['documents']:
doc['course'] = course_name
documents.append(doc)
index = minsearch.Index(
text_fields=["question", "text", "section"],
keyword_fields=["course"]
)
index.fit(documents)Create search functionality to search the documents by provided query:
def search(query):
boost = {'question': 3.0, 'section': 0.5}
results = index.search(
query=query,
filter_dict={'course': 'data-engineering-zoomcamp'},
boost_dict=boost,
num_results=5
)
return results
So here is the part where Open-Sourced LLM comes into the game:
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-xl")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xl", device_map="auto")Implement the RAG function that uses saerch, prompt construction and answer collection from the llm:
def build_prompt(query, search_results):
prompt_template = """
You're a course teaching assistant. Answer the QUESTION based on the CONTEXT from the FAQ database.
Use only the facts from the CONTEXT when answering the QUESTION.
QUESTION: {question}
CONTEXT:
{context}
""".strip()
context = ""
for doc in search_results:
context = context + f"section: {doc['section']}\nquestion: {doc['question']}\nanswer: {doc['text']}\n\n"
prompt = prompt_template.format(question=query, context=context).strip()
return prompt
def llm(prompt, generate_params=None):
if generate_params is None:
generate_params = {}
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(
input_ids,
max_length=generate_params.get("max_length", 100),
num_beams=generate_params.get("num_beams", 5),
do_sample=generate_params.get("do_sample", False),
temperature=generate_params.get("temperature", 1.0),
top_k=generate_params.get("top_k", 50),
top_p=generate_params.get("top_p", 0.95),
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
return resultdef rag(query):
search_results = search(query)
prompt = build_prompt(query, search_results)
answer = llm(prompt)
return answerllm("I just discovered the course. Can I still join in?")>>> "Yes, you are welcome to join us."So this is it! As simple as it could be. Let’s discover other options where you can obtain and run open-sourced LLMs.
LM Studio is an advanced platform designed to streamline the development, training, and deployment of language models. With LM Studio, users can easily create customized language models tailored to specific use cases, leveraging its robust infrastructure to handle large-scale data processing and model training.

You simply install LM studio on your device and search for a model you want to use or test on the main page and download it.
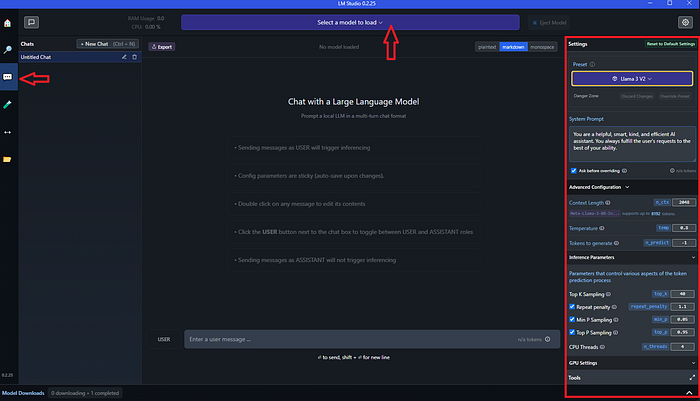
If you want to test additional functionality of the LM Studio such as chat feature, go to the chat, select the model you’ve downloaded on the previous step and if you need tweak the settings and start dialogue.
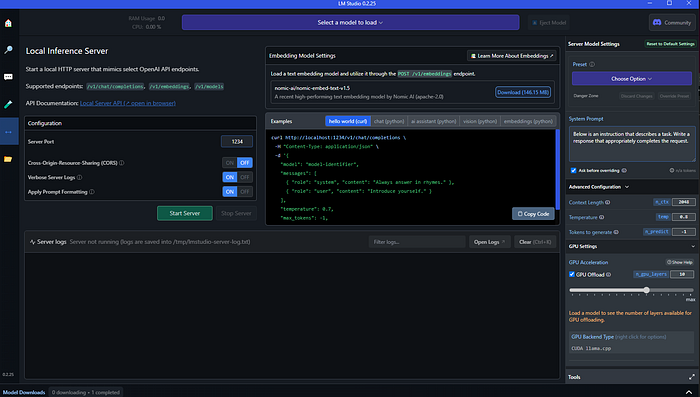
Moreover, you can easily start from out of the box the local server and run you Local Server API to test the dowloaded models in your application for example.
The LM Studio is a great tool to experiment with different LLM models on your local machine or remote server. But it does not completely suit for more complex applications and use-cases. But for experimenting with LLMs it worth it.
Ollama is the platform that similar with LM studio but has a far more functinalities. What is more important is has a lot functionality for backend serving which making this platform very useful in different situations with open-sourced LLMs. Ollama offers a comprehensive suite of tools and services that enable users to build, train, and deploy advanced language models with ease.
Additionally, Ollama emphasizes security and scalability, providing robust infrastructure to manage large datasets and ensure seamless model performance.
When you have properly installed the Ollama you can use it whether in your code or your terminal via OpenAI API, but before that you need to open terminal and download the choosen model for your use-case, e.g.
ollama start
ollama pull phi3
ollama run phi3The list of available models can be found here https://ollama.com/library
After the model was downloaded you can use it in OpenAI’s API :
from openai import OpenAI
client = OpenAI(
base_url='http://localhost:11434/v1/',
api_key='ollama',
)The second option to access ollama’s endpoint with downloaded model is to use Docker image with ollama:
docker run -it \
-v ollama:/root/.ollama \
-p 11434:11434 \
--name ollama \
ollama/ollamaAnd then open interaction mode with running image and run:
docker exec -it ollama bash
ollama pull phi3And that’s it! But it is not the all you can find a lot of use-cases on how to use ollama in different ways. From my experience it is the best tool to experiment with open-sourced models and implement it into production-based projects and to play with LLMs on the local machine.
But using the open-sourced models straight out of the box is not the best way to access the good results. In most cases you need a certain optimizations for such models for you use cases, e.g. Prompt Engineerin, Fine-Tuning, Quantization and etc. In the next section of this series I will told you about Prompt Engineering strategies and how by simply tweaking the prompt you can access the excellent results for your project.
Hope you find this information useful and helpful especially who are new in LLMs and NLP industry. In case you know another options on how to access the Open-Sourced models, please feel free to message in comments it will be usefull for community and for newbies. And do not forget to access the DataTalks community and LLM Zoomcapm here. See you!

If you liked the content or found it practically applicable and useful that’s great. You can support and inspire via BuyMeACoffe as creation of the valuable content requires a lot of efforts and time. And it is a great way to show that you are really enjoying it! Thanks!